In this article we will resolve the task of reading the “clean” text from the Office Open XML (more known as DOCX) and OpenDocument Format ODT using PHP. Note that we are not going to apply any third-party software.
You might ask, why do that? And rightly so. The clean text received from DOCX or ODT document reminds a mess. But this “mess” can then be used to create, for example, a search index for extensive document repository.
So let’s start! Both of these file formats are ZIP archives renamed into .docx/.odt. If you open these archives in, for example, Total Commander using Ctrl+PageDown, you will see the archive structure (.docx on the left, .odt on the right).
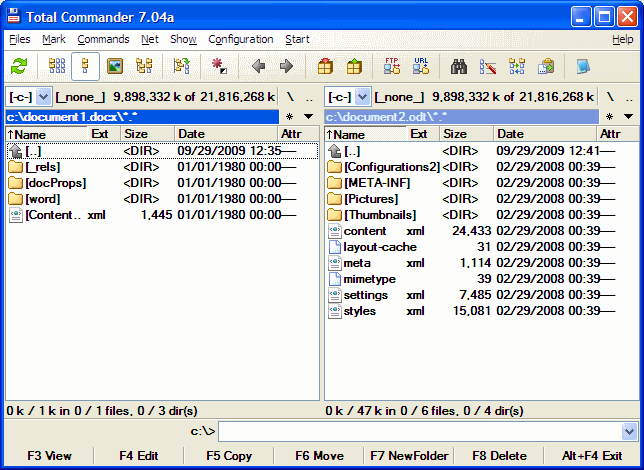
Files we are looking for are content.xml in ODT and word/document.xml in DOCX.
To read the text data from these files, we use the following code:
function odt2text($filename) {
return readZippedXML($filename, "content.xml");
}
function docx2text($filename) {
return readZippedXML($filename, "word/document.xml");
}
function readZippedXML($archiveFile, $dataFile) {
// Create new ZIP archive
$zip = new ZipArchive;
// Open received archive file
if (true === $zip->open($archiveFile)) {
// If done, search for the data file in the archive
if (($index = $zip->locateName($dataFile)) !== false) {
// If found, read it to the string
$data = $zip->getFromIndex($index);
// Close archive file
$zip->close();
// Load XML from a string
// Skip errors and warnings
$xml = DOMDocument::loadXML($data, LIBXML_NOENT | LIBXML_XINCLUDE | LIBXML_NOERROR | LIBXML_NOWARNING);
// Return data without XML formatting tags
return strip_tags($xml->saveXML());
}
$zip->close();
}
// In case of failure return empty string
return "";
} This code works in PHP 5.2+ and requires php_zip.dll for Windows or –enable-zip parameter for Linux. If you unable to use ZipArchive (old version of PHP or lack of libraries), you can use PclZip library.
Related information:
